社会工程学数据库搭建TIPS教程
最近一直在搞社工库的搭建。网上这方面也有很多文章,但是很少涉及到细节,在此与大家分享一些个人心得。
测试环境
测试坏境:windows server 2012(x64,16G 内存) ,MySQL-5.0.90,php-5.2.14-Win32
准备工具:coreseek-4.1-win32,Phantom 牛的源码
搭建过程
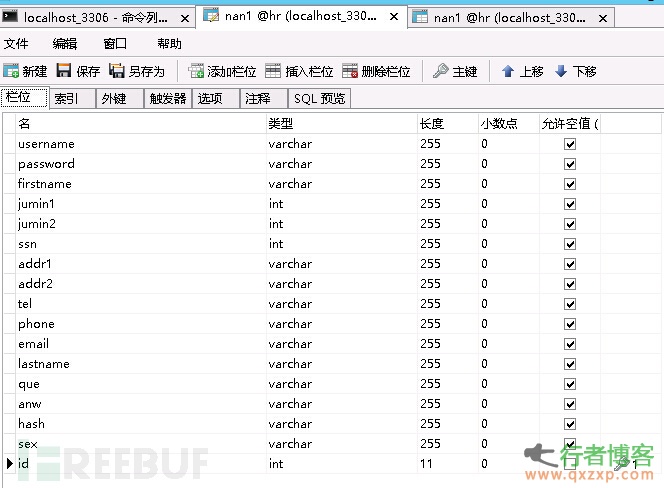
1,首先查看要索引表的字段,以便于在csft_mysql.conf 文件中配置
我们修改csft_myxql.conf 文件。(coreseek 3.2.14 不支持sql_query_string =)

注意Sql_query 中的字段必须和我们nan1 表中一致、
要支持cjk(中,日,韩简写)的查询我们必须用它的专用charset_table
因此我们应当在index mysql 中加入charset_table(因数据量过长此处就省去,请查看我
的配置文件)
2,让sphinx 支持实时索引,以便于我们后期解决某个问题。后来发现还是没有解决成功
什么是实时索引就不再纂述了:)
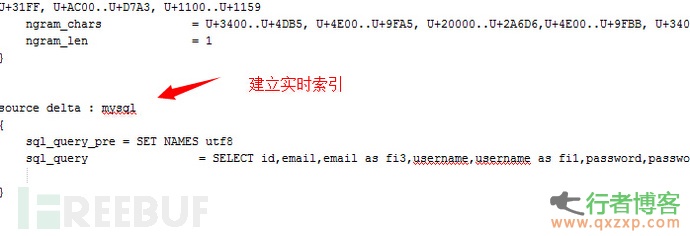
应当添加到index mysql 下方,具体请参照配置文件。修改好配置文件后请用UTF-8 without
BOM 格式保存以便程序读取配置文件。
3,建立索引,并启动
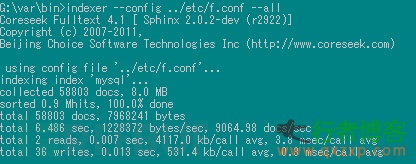
因为是测试数据量很小,因此程序启动成功
若数据量超过1 亿将显示内存不足
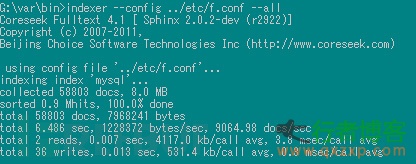
将mem_limit = 1M 设置成1M 重新建立索引,若还是提示内存不足
将表数据分割,依赖实时索引动态插入数据(ps:如果大牛还有更好的办法请与我联系)
因测试我们用nan4 表做演示
此处我们有三种方法来分割表
Code:create table nan3 select distinct
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4;
create table nan3 Select
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4 group by
firstname,lastname,email,username,password,hash,addr1,addr2,jumin1,jumin2,sex,s
sn from nan4;
//两句代码效果都一样去除username,password….sex 中内容相同的插入nan3 表,为有人
不理解我是意思,我截图示之,本人表达能力有问题
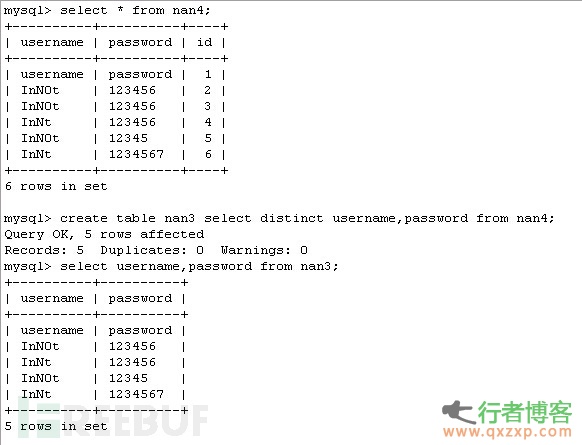
Group by 语句差不多;
昨晚喳喳同学告诉了我一个直接去除表中重复内容的语句我也贴上来,感谢他了(ps:和他研究了一晚上,没办法啊,人笨。)
Code:delete from temps where id in (select id from (select
id from temps as s where (select count(*) from temps as a
where a.username=s.username and a.password =s.password)>1
and id not in(select id from(select id,count(distinct username,
password) from temps as s where (select count(*) from test4
as a where a.username=s.username and a.password =s.password
)>1 group by username) as sss))as ttt)
注意:此处id:需为自增ID
分割表时不要用limit 参数与distinct 参数混用容易造成卡死,且得多次去重
create table tempss select * from nan3 limit 0,3;
create table temp select * from nan3 limit 3,5;
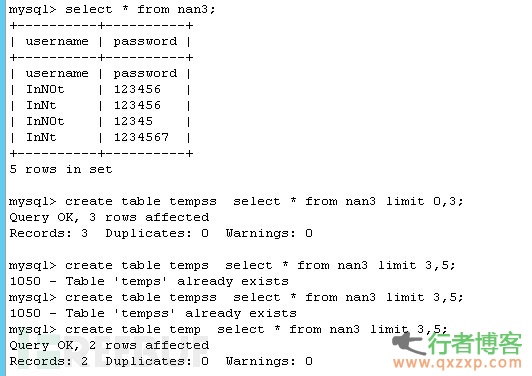
OK,现在我们已经分成两个表,并手动给两个表添加自增ID(temp id 最大值为4,temps id 最小值为5),我们将一个temp 表建立索引,并启动
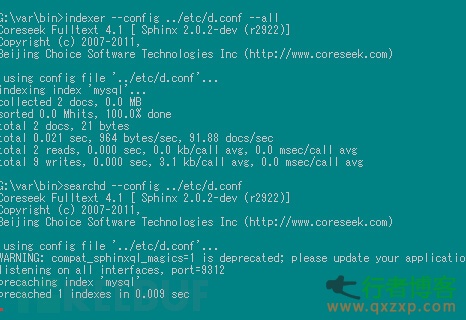
话说不知道是我人品的问题还是那啥,因此我们需要稍改一下search.php 的源码
搜索结果
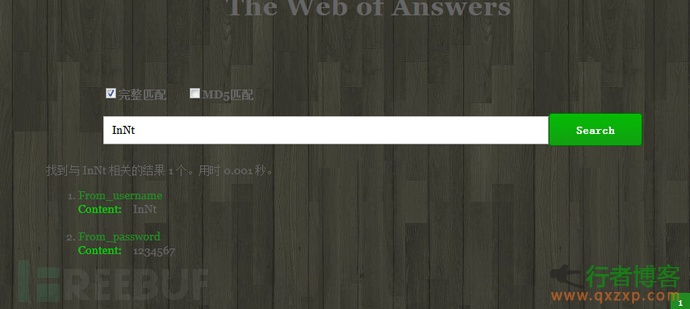
insert into temp select * from tempss;//将tempss 的数据插入到temp

插入后搜索结果
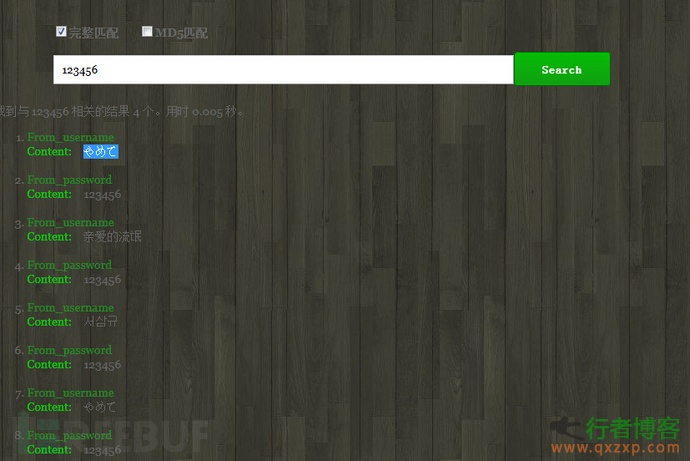
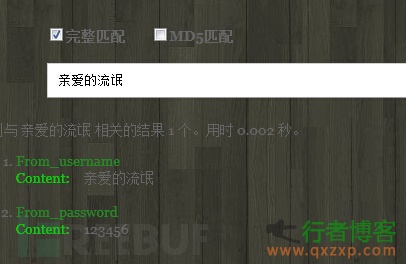
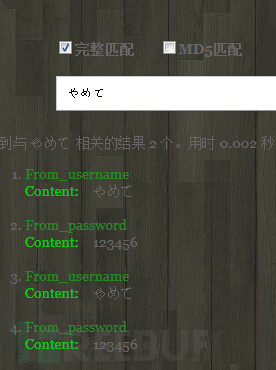
我对不起大家经过我的测试实时索引重启后还是出现内存不足的情况,且只能修改我们索引
后的id 对应字段参数值。(留待大牛解答了)
补充TIPS
如果你恰好有韩国的或者小日本的数据库,又恰好的先导入进去了(入库没啥好说的,数据库编码最好统一为utf8),编码也设置成949
或者euckr
可能下面的语句能帮到您:
create table test4 select username ,password from test1 union
select username,password from test2;
//将test2 表与test1 表比较清除重复后插入test4 中;(ps:字段数据类型可
以不同)
ALTER TABLE test4 DEFAULT CHARACTER SET utf8 COLLATE utf8_gen
eral_ci;
//不解释
alter table nan1 modify column username varchar(50); //修改username 的数据类型
alter table $table add $username varchar(50) null; //添加新字段
工具下载地址:http://pan.baidu.com/s/1ntkftsX 密码:pcrh
参考文章
http://blog.csdn.net/rulev5/article/details/7572482
http://tesfans.org/using-sphinx-search-engine-with-chinese-japanese-and-korean-language-docume
nts/
http://zone.wooyun.org/content/9377
感谢,北极熊,SBY 对我问题的细心解答,感谢喳喳,和老大。
欢迎志同道合的朋友与我交流:InN0t@outlook.com,作者:InN0t
[本文由作者InN0t撰写并投稿FreeBuf,版权属于InN0t,转载请注明来自FreeBuf.COM]
原创文章转载请注明:转载自 七行者博客
本文固定链接: https://www.qxzxp.com/5734.html